
差异基因千千万?富集分析教你抓重点!
一、差异基因多到眼花缭乱,怎么办?
在科研实验中,尤其是RNA-seq、转录组学或者芯片数据分析中,差异基因(Differentially Expressed Genes, DEGs)几乎是“标配结果”。
比如,一个癌症患者与健康对照相比,可能会发现上千甚至上万个差异基因。
问题来了:
- 这些差异基因究竟说明了什么?
- 它们之间有没有共同的规律?
- 哪些基因才是真正关键的,而不是噪音?
这时候,如果我们只是一味去“盯”某一个或几个基因,很容易陷入“盲人摸象”。而富集分析(Enrichment Analysis),就像是一盏探照灯,能帮我们从基因的“汪洋大海”中,快速找到有价值的方向。
二、什么是富集分析?
简单来说,富集分析就是:
看差异基因是否在某些功能、通路、调控网络中出现得“特别多”,从而提示它们背后潜在的生物学机制。
常见的富集分析主要包括三类:
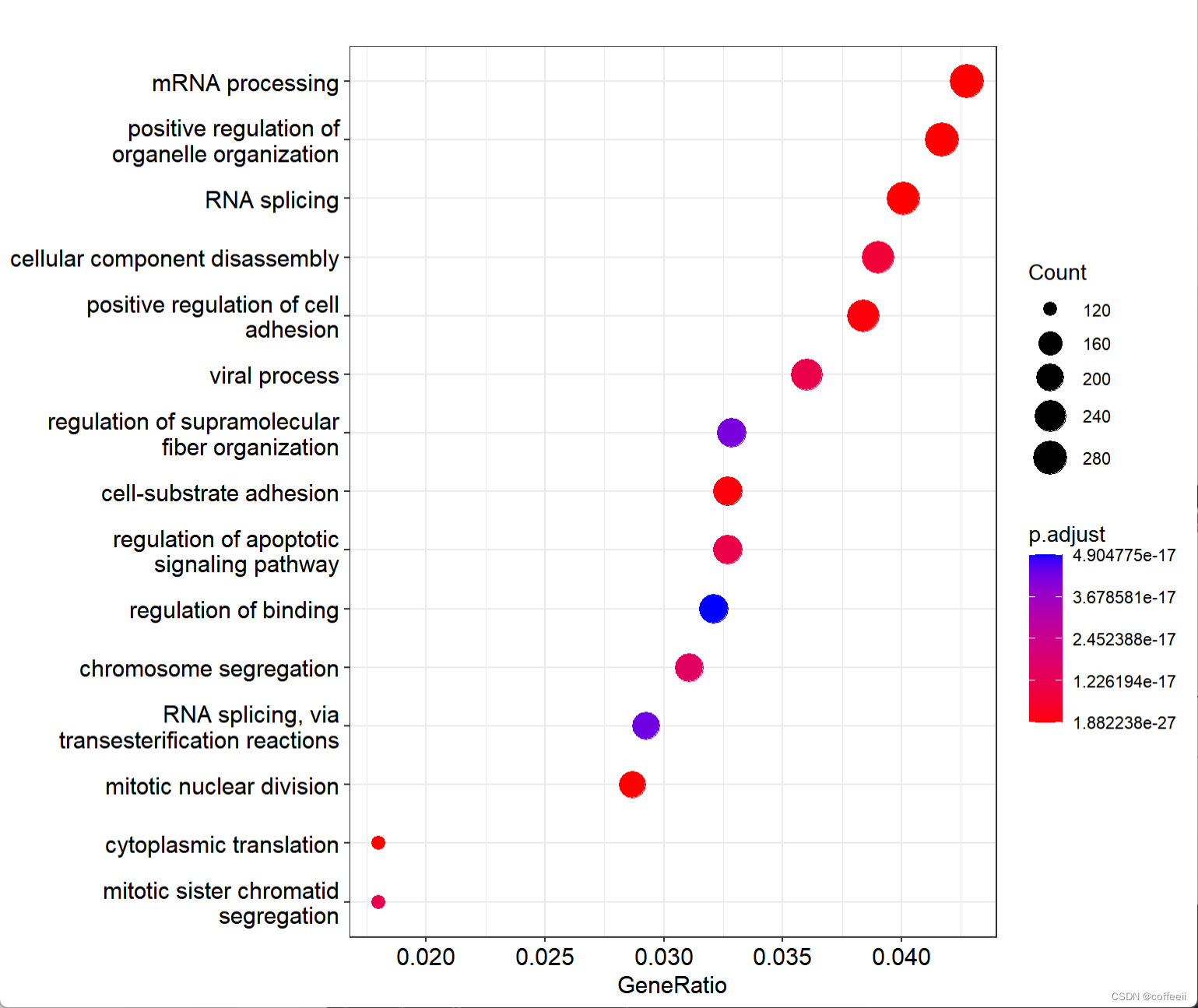
- GO 富集分析(Gene Ontology)
- 从“基因功能”的角度出发。
- GO 包含三大类:
- BP(Biological Process,生物学过程):基因参与的生物学事件,比如“细胞凋亡”、“炎症反应”。
- MF(Molecular Function,分子功能):基因编码蛋白的功能,比如“ATP结合”、“DNA结合”。
- CC(Cellular Component,细胞组分):基因产物存在的位置,比如“细胞膜”、“线粒体”。
👉 通过GO富集,我们能回答:这些差异基因主要参与了哪些功能过程?
- KEGG 通路分析(Kyoto Encyclopedia of Genes and Genomes)
- 从“通路”的角度理解基因作用。
- KEGG收录了各种经典通路,如“PI3K-Akt信号通路”、“细胞周期”、“糖酵解/糖异生”等。
👉KEGG告诉我们:这些基因在哪些信号通路上“扎堆”。
-
- GSEA(Gene Set Enrichment Analysis)
- 一种更先进的思路,不依赖“差异基因筛选”,而是看整个基因表达矩阵是否在某些功能/通路上整体偏高或偏低。
👉适合发现“隐藏”的趋势,而不仅仅是显著差异的基因。
三、为什么要做富集分析?
如果说差异基因是“名单”,那富集分析就是帮你看名单背后的故事。
举个例子:
- 如果你在肿瘤样本中发现了2000个差异基因,结果发现它们显著富集在“细胞周期通路”、“DNA修复通路”,那基本能说明:这个肿瘤可能因为异常的增殖、修复机制出问题而发展。
- 如果你在免疫疾病中发现的差异基因富集在“Th17细胞分化”、“炎症因子信号通路”,那可能提示免疫调控紊乱是病因关键。
换句话说,富集分析不是帮你确认某个基因,而是帮你抓到“机制”与“方向”。
四、富集分析的流程
做一次标准的富集分析,大致需要这几个步骤:
- 准备差异基因列表
- 通常来自DESeq2、edgeR等差异分析软件。
- 需要设定阈值(如 |log2FC| > 1,FDR < 0.05)。
- 选择背景基因集
- 一般用全基因组作为背景,但有时也会用实验测序到的所有基因。
- 使用数据库
- GO数据库(Gene Ontology)
- KEGG数据库
- Reactome、MsigDB 等扩展数据库
- 统计检验
- 超几何分布、Fisher精确检验、校正P值(FDR、Bonferroni等)。
- 可视化结果
- 富集条形图(barplot)、气泡图(bubble plot)、网络图(network plot)。
- 用R包 clusterProfiler 是常见选择。
这样,就能得到一份“差异基因的功能画像”。
五、案例分享:从千基因到关键通路
假设我们研究的是胰腺癌。
- 差异分析后,得到 1500个差异基因。
- 通过GO分析,发现这些基因显著富集在:
- “细胞周期调控”
- “细胞外基质组织”
- “凋亡过程”
- 通过KEGG分析,发现:
- PI3K-Akt 信号通路
- MAPK 信号通路
- ECM-受体相互作用
解读:
胰腺癌的恶性增殖,和异常信号通路激活高度相关,同时细胞外基质的改变可能促进转移。这些发现不仅印证了已有研究,也可能提示新的治疗靶点。
如果进一步用GSEA,还能看到:
- “上皮-间质转化(EMT)”相关基因集整体上调。
👉这进一步支持了转移潜能增强的结论。
这样,原本1500个基因的“迷雾”,被压缩成了几个“可解释的机制”,研究方向就一下子清晰了。
六、富集分析的应用场景
- 疾病机制研究
揭示疾病背后的信号通路和调控网络。 - 药物靶点预测
富集结果中高频出现的通路,往往是潜在的干预靶点。 - 生物标志物筛选
如果某些功能/通路在患者组中特异上调,可以进一步寻找核心基因作为诊断或预后标志物。 - 跨研究整合
不同队列的差异基因可能不同,但富集通路往往一致。
👉富集分析帮助我们抓到“共性机制”。
七、需要注意的“坑”
- 差异基因阈值过松/过严
- 太松:噪音太多,结果泛化。
- 太严:错过潜在关键基因。
- 背景基因集不当
- 如果实验平台检测不到某些基因,却用全基因组做背景,可能引入偏差。
- 数据库版本问题
- 数据库要更新,否则可能遗漏最新知识。
- 过度解读
- 富集结果提示的是“可能相关”,不是因果关系。
- 需要结合实验验证。
八、总结
一句话概括:
差异基因只是“名单”,富集分析才是“导航”。
它能帮我们从千千万的差异基因中,快速定位到:
- 哪些功能过程被破坏?
- 哪些信号通路被激活?
- 哪些潜在机制值得深入?
对科研新人来说,富集分析是理解数据的第一步;对资深研究者来说,它是把复杂数据转化为生物学故事的“桥梁”。
所以,下次当你面对成百上千的差异基因时,别慌——用富集分析,先抓重点,再逐步深入。